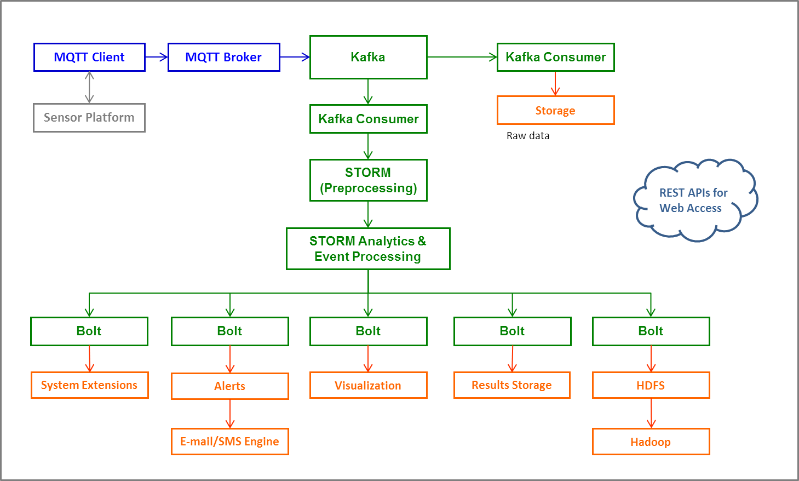
Kafka Storm HDFS Architecture Design
Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比较简单,实际编程开发起来相对容易。下面,简单介绍编程实践过程中需要理解的Storm中的几个概念:
Topology
Storm中Topology的概念类似Hadoop中的MapReduce Job,是用来编排容纳一组计算逻辑组件(Spout,Bolt)的对象(Hadoop MapReduce中一个Job包含一组Map Task、Reduce Task),这组计算组件可以按照DAG图的方式编排起来(通过选择Stream Groupings来控制数据流的分发流向),从而组成一个计算逻辑更加负责人的对象,那就是Topology。一个Topology运行以后就不能停止,它会无限地运行下去,除非手动干预(storm kill)或者意外故障(停机、集群故障)让他终止。Spout
Storm中Spout是一个Topology的消息生产的源头,Spout应该是一个持续不断生产消息的组件,例如,它可以是一个Socket Server在监听外部Client连接并发送消息,可以是一个消息队列(MQ、Kafka)的消费者、可以是用来接收Flume Agent的Sink所发送消息的服务,等等。Spout生产的消息在Storm中被抽象为Tuple,在整个Topology的多个计算组件之间都是根据需要抽象构建的Tuple消息来进行连接,从而形成流。Bolt
Storm中消息的处理逻辑被封装到Bolt组件中,任何处理逻辑都可以在Bolt里面执行,处理过程和普通计算应用程序没什么区别,只是需要根据Storm的计算语义来合理设置一下组件之间消息流的声明、分发、连接即可。Bolt可以接收来自一个或多个Spout的Tuple消息,也可以来自多个其它Bolt的Tuple消息,也可能是Spout和其它Bolt组合发送的Tuple消息。Stream Grouping
Storm中用来定义各个计算组件(Spout、Bolt)之间流的连接、分组、分发关系。Storm定义了如下7种分发策略:Shuffle Grouping(随机分组)、Fields Grouping(按字段分组)、All Grouping(广播分组)、Global Grouping(全局分组)、Non Grouping(不分组)、Direct Grouping(直接分组)、Local or Shuffle Grouping(本地/随机分组),各种策略的具体含义可以参考Storm官方文档、比较容易理解。
Storm是由一个或者多个Spout和多个Bolt组成一个数据流向图,整个图就通过Topology来显示的声明,数据在流动的过程中,会经过各种数据处理逻辑单元;官网给的图片就能很好的说明Storm的设计原理;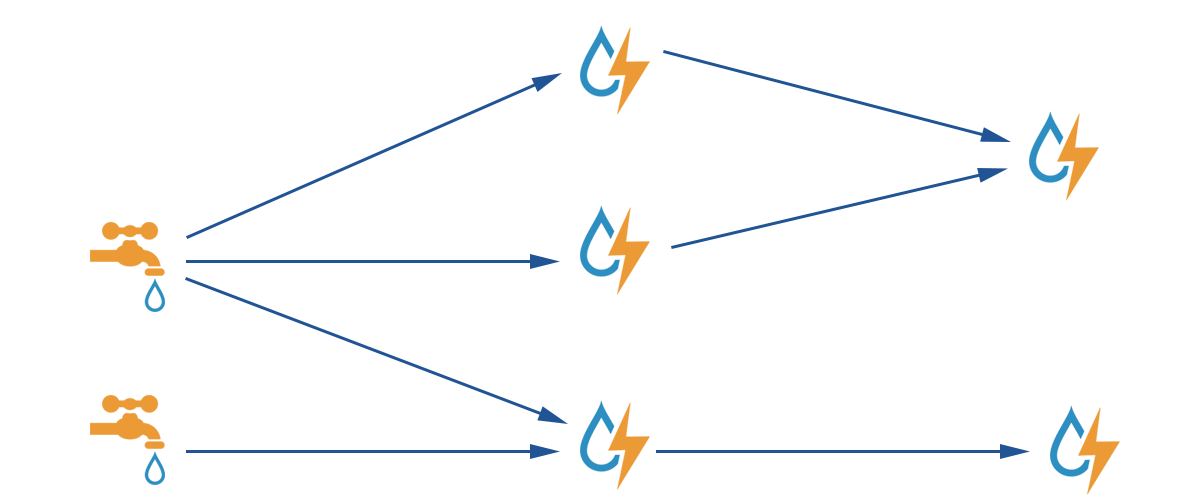
我在很久以前就通过Storm来解决实际生产问题,发现他真的帅呆了,并且简单易用、灵活定制,如果你还没有开启Storm,那就通过本篇内容开始流计算之旅,帮助你在生产环境中不断取得成功;
Storm在我看来就是一套数据循环系统,在数据的流动过程中,就处理了数据,数据最终流动到终点的时候,就可以对外提供决策支持或可视化。
Storm根据官网的图片理解,自来水厂送水到客户家;水的源头到最终到达客户,会经过很多的自来水净化站,自来水消毒站点等各种站点。水源即为我们的Spout,净化自来水的站点即为Bolt,Bolt净化出不同程度的水继续往那个方向流动以什么方式流动到下一个站点即为Stream Grouping。
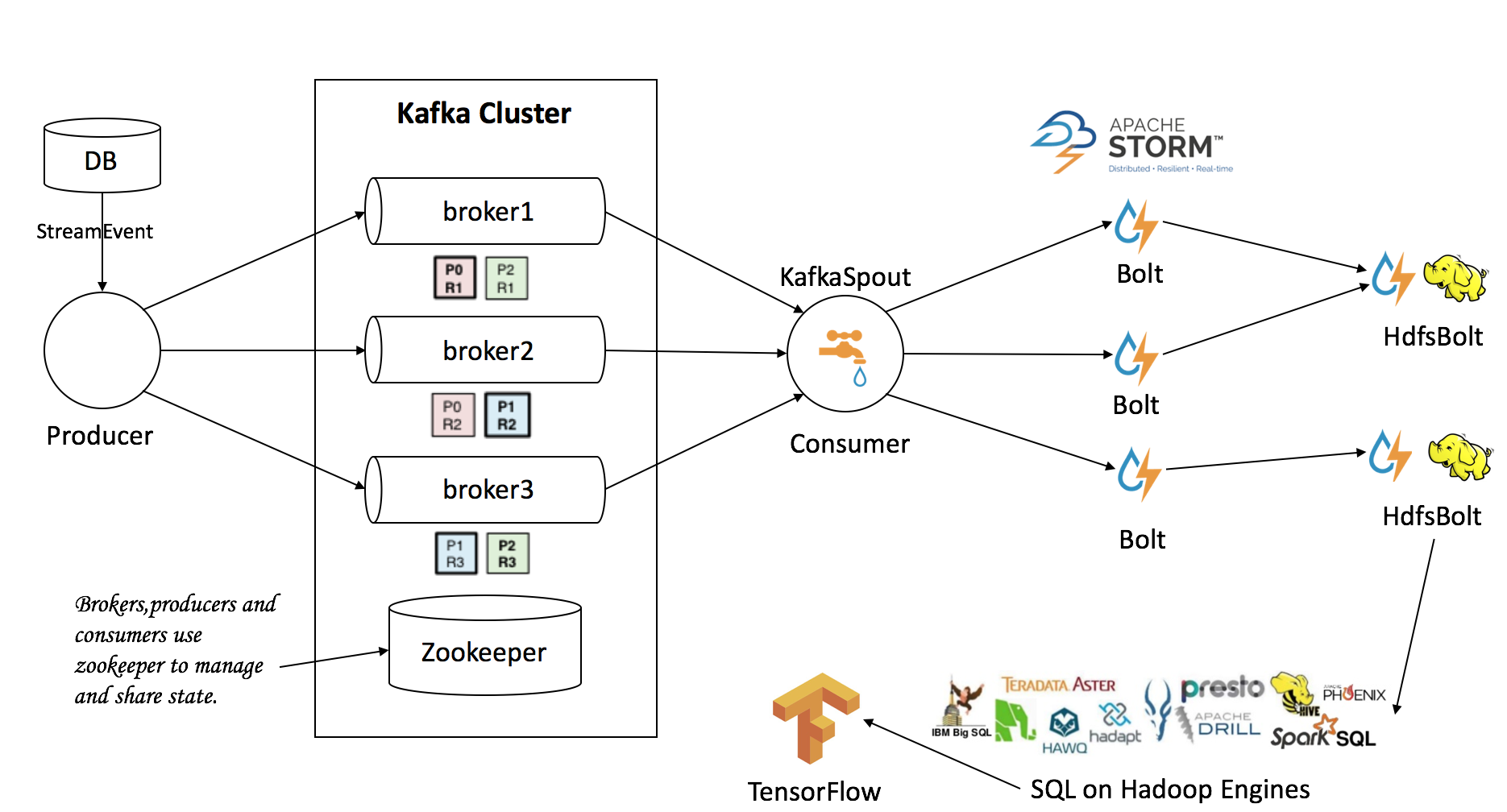
Storm中Spout对接源头数据(Kafka,HDFS,DB,MQ,Socket); Bolt(接收处理Spout/Bolt数据)具体的业务逻辑处理;Stream Grouping数据分发策略,以什么方式发送数据流到下一个Bolt。下面我们以一个具体的案例来说明Storm的实际生产应用。
1 | TopologyBuilder builder = new TopologyBuilder(); |
如上代码所示,即为Topology,按照DAG图的方式编排计算组件的数据流向;Topology任务提交有两种LocalCluster和Cluster(StormSubmitter)
KafkaSpout组件
接收Kafka某一个topic中的数据,发送到下一个业务逻辑组件CheckOrderBoltCheckOrderBolt组件
接收KafkaSpout发送数据,检测数据为当天数据,否则不处理;处理后发送CountBolt组件CountBolt组件
接收CheckOrderBolt组件处理后发送过来的数据,发送给HdfsBolt组件HdfsBolt组件
接收CountBolt组件处理后发送过来的数据,以一定的规则(1分钟生成一个带时间戳的文件或者每5MB大小自动写下一个文件)写入HDFS,比如本文示例代码。
KafkaSoput代码示例:1
2
3
4
5
6
7
8
9String zkhost = "wxb-1:2181,wxb-2:2181,wxb-3:2181";
String topic = "order";
String groupId = "id";
int spoutNum = 3;
int boltNum = 1;
ZkHosts zkHosts = new ZkHosts(zkhost);//kafaka所在的zookeeper
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/order", groupId); // create /order /id
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
HDFS Bolt代码示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// use "|" instead of "," for field delimiter
RecordFormat format = new DelimitedRecordFormat()
.withFieldDelimiter("|");
// sync the filesystem after every 1k tuples
SyncPolicy syncPolicy = new CountSyncPolicy(1000);
// rotate files when they reach 5MB
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(5.0f, FileSizeRotationPolicy.Units.MB);
// FileRotationPolicy rotationPolicy = new TimedRotationPolicy(1.0f, TimedRotationPolicy.TimeUnit.MINUTES);
FileNameFormat fileNameFormat = new DefaultFileNameFormat()
.withPath("/tmp/").withPrefix("order_").withExtension(".log");
HdfsBolt hdfsBolt = new HdfsBolt()
.withFsUrl("hdfs://wxb-1:8020")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
CountBolt代码示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class CounterBolt extends BaseBasicBolt {
private static final long serialVersionUID = -5508421065181891596L;
private static Logger logger = Logger.getLogger(CounterBolt.class);
private static long counter = 0;
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
List<Object> data = tuple.getValues();
String id = (String) data.get(0);
String memberid = (String) data.get(1);
String totalprice = (String) data.get(2);
String preprice = (String) data.get(3);
String sendpay = (String) data.get(4);
String createdate = (String) data.get(5);
collector.emit(new Values(id,memberid,totalprice,preprice,sendpay,createdate));
logger.info("+++++++++++++++++++++++++++++++++Valid+++++++++++++++++++++++++++++++++");
logger.info("msg = "+data+" ----@-@-@-@-@--------counter = "+(counter++));
logger.info("+++++++++++++++++++++++++++++++++Valid+++++++++++++++++++++++++++++++++");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id","memberid","totalprice","preprice","sendpay","createdate"));
}
}
本文代码完整示例:https://github.com/itweet/storm-kafka-examples1
git clone [email protected]:itweet/storm-kafka-examples.git
通过IntelliJ IDEA导入已经存在的Maven等待依赖下载,通过运行maven package打包命令,在target目录jar文件上传集群运行。
运行代码示例条件,具备Storm,Kafka,Hadoop,Zookeeper环境,在zk中首先创建好node,进入zookeeper-cli后执行create /order /id命令。
测试
send msg to kafka
1
storm jar storm-kafka-examples-1.0-SNAPSHOT.jar cn.itweet.sendmsg.SendMessageKafka
storm processing data
1
storm jar storm-kafka-examples-1.0-SNAPSHOT.jar cn.itweet.kafka_storm.topology.CounterTopology
Processing data to HDFS,Running results
hadoop fs -ls /tmp/order_hdfs-xxx.log
实时处理,开发满足业务需要的Topology,通过代码大家可以看到,Storm大道至简的设计理念,通过实现不同的Bolt处理数据,让数据在流动的过程中完成数据处理;简洁、灵活、定制化,提供丰富的数据源,甚至StormSQL,更多内容请参考官方文档。
Storm-External: https://github.com/apache/storm/tree/master/external
如上,给出了简单Storm的示例代码,可以在这个基础上加入业务逻辑内容,就可以完成如下复杂的业务处理,基于非结构化数据(GPS位置应用),实时流处理的架构。