Micro-service architecture based on restful
经过2个多月的研发周期,上周六发布了关于AI赋能的数据平台的产品。
最近码子频率低很多,天天码代码。衰~
今天,我们来谈谈微服务架构。
微服务架构,所有服务基于restful相互访问,部署模式全容器化,k8s进行调度。
从整体来看,这样的设计符合目前服务容器化的大趋势,我们一路采坑踩。
我曾经一直从事大数据平台产品的研发和设计工作,但是个人对于容器技术一直秉承谨慎的态度。
因为我做的是数据的持久化系统,而容器在我看来只能跑一些无状态的服务,有状态需要持久化的系统不应该放到容器中运行。
并非我以前没有使用过容器或者k8s系统,认知不够, 我们就此讨论一下。
Why Docker
我曾经构建过基于docker实现的持续集成平台,效果非常显著,基于docker的application部署,简直是开发者的福音。
没有docker技术之前,一千个开发者有一千种部署application的方式,为了要部署上各种application,浪费大量时间调试。
也有一些其他解决方案,比如rpm/deb标准化的包,通过一些shell/python/ruby脚本控制,已经比较方便了,部署需要修改一堆参数,稍有不慎就是各种错误。
docker技术可以说给所有的application部署提供的一套标准方案,只需要安装dockerfile编写需要打包的内容、依赖、启动脚本,然后docker build就可以生成docker image.
由于docker做到了环境独立,通过docker image,到任何一台安装的docker的机器,直接docker pull && docker run 就可以开始愉快的体验和使用application。
可以说docker为复杂的应用部署提供了一套标准化的解决方案,而且是比较一次性彻底的解决方案。
有些类似曾经的rpm/deb系统包,你现在只需要一个docker image,就可以把应用部署起来,并且保障可用性和容易维护,前提是你已经安装好docker服务。
我是一个分布式持久化数据存储系统的,对于容器化部署,探索一段时间,感觉多年研发的软件架构上需要重新调整适应容器化的特点。
近年来实现的新软件,基本都可以支持容器化部署,而对于Hadoop Ecosystem显然比较得不偿失。
并非无法实现,而是因为性能、稳定性、持久化存储、网络、DiskIO等多方因素,容器化后是否依然高效。
如果硬上也是可以的,前几年我们也见识过Mesosphere公司基于Mesos核心,提出过一个新的概念数据中心操作系统DC/OS,国内也有团队曾经出来分享基于DC/OS实现的全容器化的topic。
几年一晃而过,已经没啥声音,不知道用的怎样了,全容器化的数据服务,大家都比较谨慎吧。
Why k8s
k8s 全称kubernetes,是Google开源的容器调度系统,功能很强大,涉及的知识也非常多,索性在1年多前研究过k8s,当时安装和使用成本还比较高,所以当时就没有上k8s,仅仅上了docker,
用来做公司内部的持续集成平台,帮助提缩短品研发周期,构建强大的自动化测试发布系统。
k8s给我的感受,实现的越来越复杂,功能也越来越强大,目前基本k8s已经是容器化调度的核心标准。容器集群都是基于k8s来做,我个人并没有很多k8s的使用经验,简单谈几点感受。
k8s真正解决了容器化后应用的管理和维护问题,可以基于 restful 传递 template 帮助管理容器,让大规模容器化的使用和维护成为可能。
k8s管理很多无状态服务,可以大大缩短application的发布和部署周期,让一天持续发版上线成为可能,并且容器中任务的运行情况监控变得容易。
k8s系统可视化界面还比较简单,主要是使用方式,基本要很好的使用符合自己公司业务,需要自己基于client封装一层,用起来更爽,不对业务造成负担。
k8s持久化存储,底层可选的方案:ceph、glusterfs、nfs、local storage等方案。
k8s容器化调度,如果不是大规模镜像创建和管理,建议轻易不要上k8s,维护不易,如果资源不足,使用起来很痛苦。
restful 微服务
终于进入正题,我们所有的服务都是容器化部署,基于k8s部署管理。
跑在容器内部的提供restful服务的全都采用SpringBoot实现,而且几十个微服务化的组件都是基于restful的接口进行沟通,导致整体项目复杂度
特别大,部署、restful接口之间调用成本大大增加, 接口变更,上下游的依赖服务比较痛苦,特别是如果没有及时通知变更,导致异常情况,而
整体又没有定义异常约束状态,让我意识到,HTTP statusCode的定义和规范异常重要,不然各个微服务系统自己独立一套异常处理逻辑,微服务之间
相互调用成本又进一步增加,每次测试上线,成本异常高昂。
微服务化,系统之间相互依赖,API层层转发,也是一个非常大的成本,只要一个服务不work,导致整个请求完全失败,如果测试的时候没有覆盖,各个服务down情况,上线是一个非常大的坑。
微服务化,系统之间调用的容错性处理,也是需要提前设计和规避的,或者说是一些约定和规范。
微服务化,服务之间约定的全局状态同步,是一些很小的数据,但是必须全局一致性,需要持久化,但是容器化之后,持久化变得有些不可靠。
微服务化,数据计算或数据同步类容器,基于Java开发,如果资源给得比较小,容易出现oomkilld的情况,需要动态控制容器资源,目前还不太容易控制,
因为,不同数据量的冲击和资源的配比不合理可能导致频繁的oomkilld,只能在创建容器的时候可以通过config配置cpu, memory的值,并且调节jvm的一些
参数进行优化和资源GC控制,但是如果容器内部有特别大的数据量,也不是很好控制,只能限流,降低数据拉取速度,数据计算和同步容器对系统的压力比较大,
虽然容器化,确实能做资源隔离,但是大量容器的创建和使用,经常导致容器limit,cpu达到百分之几百,而导致后续容器无法正常创建出来。
海量的容器创建和管理,虽然有k8s,但是也不是那么容易管理好,需要有充足的资源和使用规划,出现大量的野容器和野数据,是一种资源的浪费。
由于大量微服务相互依赖,需要相互获取一些全局信息,大家比较系统把它注入到全局的环境变量中,代码中获取环境变量即可拿到值,虽然很方便,但是
也让我踩到一个大坑,就是环境变量冲突,我在springboot的application-dev.yaml中配置的变量,springboot会在启动的时候注入到环境变量中,但是被
其他服务复写了,导致我获取到错误的值,服务发布上线后导致整个系统down掉,排查良久,坑…,也是一些规范和约束的问题吧。如果能引入一个全局
的配置中心,可以自动发现和管理所有服务的配置,并且配置变更能主动通知变化,无疑是更好地方案,但是使用成本不见得低,都是权衡的问题吧。
关于springboot环境变量和配置变量的关系,详见:https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-external-config.html
微服务化,统一权限控制服务,是一个极其重要和讲究的模块,主流的基于API的鉴权,主要是:JWT Token,Oauth 2.0 对数据加密传输,完成鉴权,实现起来可复杂可简单,
主要是支持跨域验证的问题,服务都是restful的设计,必然需要前后端分析,引入ng5/react前端框架,整体复杂度又上一个台阶。
微服务,依赖太多容器外部服务,数据相关依赖Hadoop Ecosystem,需要选定一个发行版进行兼容,通过一些强大的基础软件系统帮助更好地解决智能化数据分析过程。
总结
关于数据平台,基本都是私有化部署,容器化比较困难,而一些计算类的算子、AI算法或者Long service,完全容器化,便于管理和发布。
目前Hadoop Ecosystem + AI, 正如火如荼发展,也出现了一些不同的发展方向。
A类,公司让YARN调度Docker,实现AI算法和YARN融合和Hadoop融合,耦合紧密,改造时间和难度大,Hadoop 3.0已初步支持。
B类,公司让k8s调度Docker,实现AI算法和K8s融合,远程加载Hadoop ecosystem数据,耦合没那么紧密,可独立发展。
那么,我们今天引入一个新的话题,AI数据平台应该怎么做?主流的做法有哪些?有哪些讲究?
我上半年有做过一个开源数据平台,主打Core Data + Core AI设计: 企业级 Core Data & Core AI 流分析平台
其中,关于Yarn内容可忽略,主要是海量数据理想跑批、Core AI融合Yarn跑模型使用的,需依赖Hadoop Ecosystem,开源的版本中未提供。
开源主要提供Core Data,在未来的版本中会支持升级版混合数据存储加AI功能的版本, 希望有时间吧。
先上图,且听下回分解:
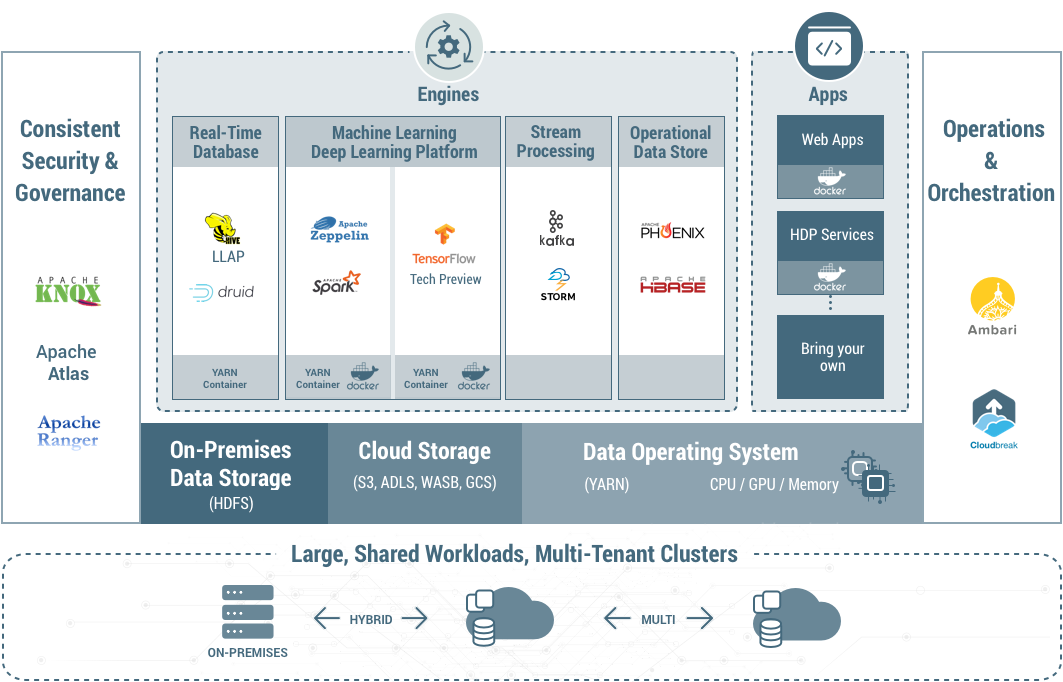
A方案: Hadoop+AI,在YARN改造支持容器调度,YARN往通用的资源管理调度框架发展,轻松移植各类AI框架和算法到分布式系统。
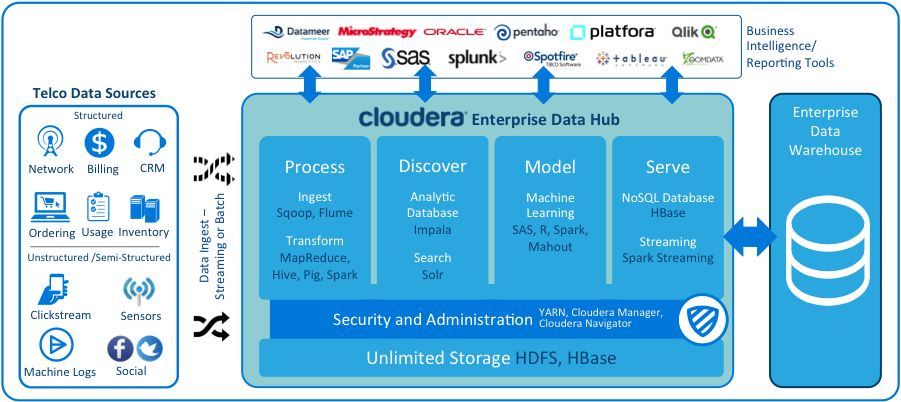
B方案: Hadoop+AI,data-platform和machine-learning分开调度,一个基于k8s容器化算法,提交任务到spark on yarn,或者ML/DL on Yarn上。
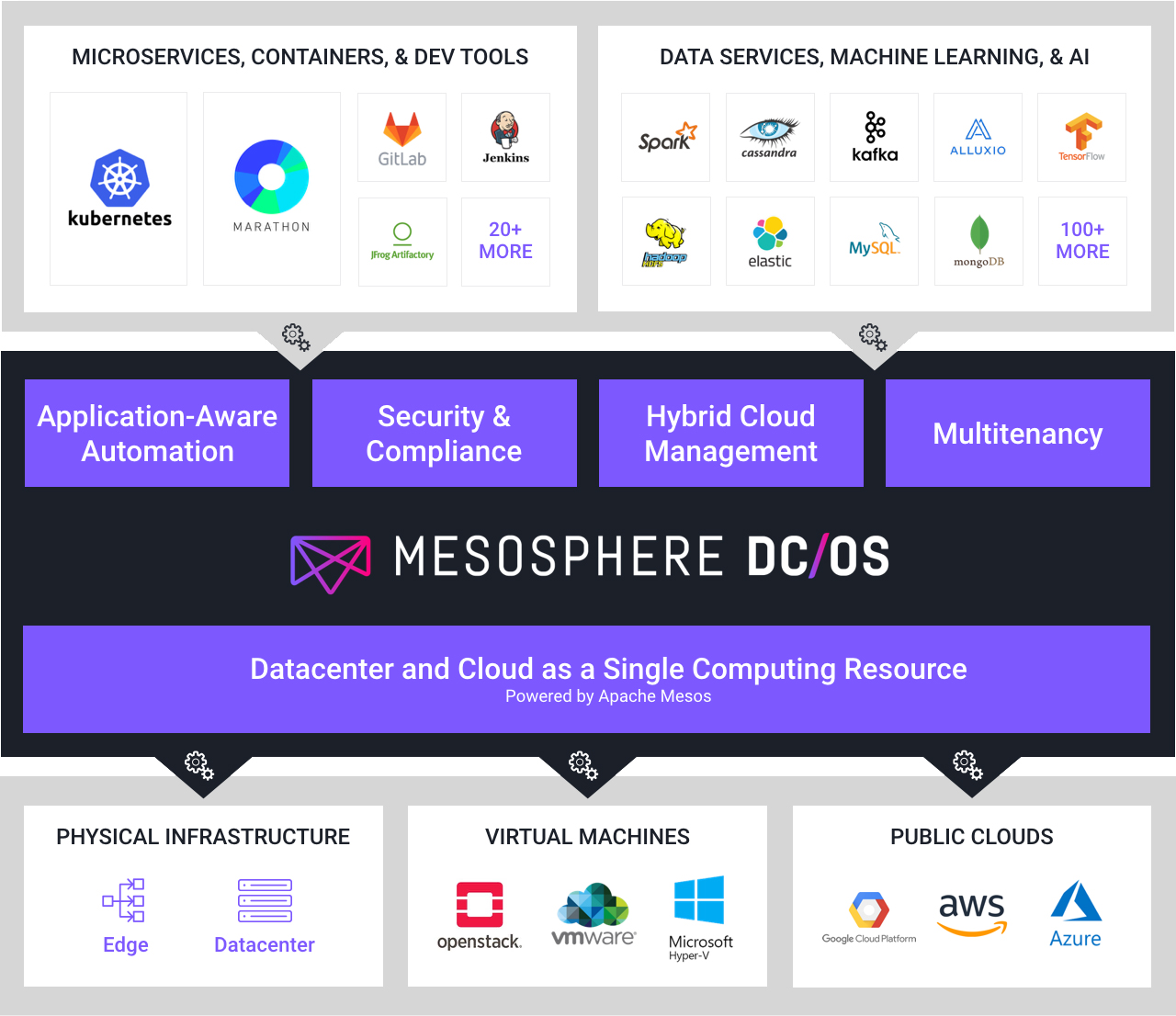
C方案: DC/OS,一套数据中心操作系统方案,也是基于容器化,比较彻底。