Parquet-library-fatal-error
parquet-Hadoop 1.9.0 大量close-wait问题。
一个开源基础库引发的严重产品事故,整个事件场内block超过4小时以上。
我们某服务部署上线,界面化的DAG任务,主要跑机器学习全流程作业,运行一段时间,发现后端数据平台查询、预览数据功能全部不可用,导致大量上游业务系统block住。
报错关键信息:
- UnknowHostException
1 | java.net.UnknownHostException: node199mm1002 |
排查Hadoop集群平台是否正常,如上主机是否可到达,发现均正常,集群无问题。
- Too many open files
1 | java.net.SocketException: Too many open files; Host Details: local host is : "java.net.UnknownHostException: tserver-98989-bmhtk: tserver-98989-bmhtk: System error": destination host is: "node199mm1002":25000; |
操作系统,根据ulimit -a查看系统fd配置,主机fd上限为640000,tserver容器的fd上限为65536。通过kubectl进入tserver容器,使用命令“watch ‘ss | grep CLOSE-WAIT | wc -l’”查看,发现65278个close-wait,快崩了。
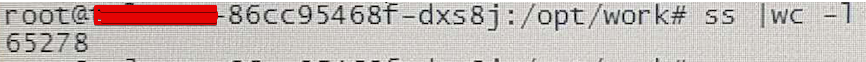
基本可确定是大量,close-wait连接泄漏问题,对连接泄漏列表进一步分析:
1 | ss | grep CLOSE-WAIT > close_wait.txt |
发现两个特征,一个是属于http相关相关close-wait,占比2%,剩余的全是连接50010端口出现的close-wait,查询Hadoop相关端口,发现50010是DataNode的数据转发端口,初步怀疑是代码连接Hadoop DataNode查询数据没有关闭流导致。
- DataManager Service:listFiles error IOException
排查DataManager Service相关代码,发现listFiles函数,主要功能,读取HDFS获取某个目录下的parquet集合,然后进行读取parquet的meta信息,前端进行展示大小,行数,还会读取任意问题进行预览,或者随机预览数据。
并未发现有任何异常情况,系统每次调用此接方法导致阻塞,一步步跟进调试,发现已经进入parquet相关的代码。
经过认证检查每一行代码,发现流相关操作均进行了关闭,并没有任何问题。
验证思考:缩小问题范围,对listFiles函数,调用的全部方法进行最小化单元测试,最终在开发环境preview方法中,实现了连接HDFS读取parquet文件,使用rest接口,单独调用此方法,每次调用close-wait都会增加2,并且长期存在。
监控命令“watch ‘ss | grep CLOSE-WAIT | wc -l’”,疯狂访问,一直增加不曾下降。
猜测是Parquet依赖库,有连接泄漏问题,于是向社区求助,我们引入的parquet 1.9.0上下几个版本的commit以及bugfix全看了一遍,重点关注close stream相关。
PR PARQUET-783 提到相关问题:
···
This PR addresses https://issues.apache.org/jira/browse/PARQUET-783.
ParquetFileReader opens a SeekableInputStream to read a footer. In the process, it opens a new FSDataInputStream and wraps it. However, H2SeekableInputStream does not override the close method. Therefore, when ParquetFileReader closes it, the underlying FSDataInputStream is not closed. As a result, these stale connections can exhaust a clusters’ data nodes’ connection resources and lead to mysterious HDFS read failures in HDFS clients, e.g.
org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-905337612-172.16.70.103-1444328960665:blk_1720536852_646811517
···
根据社区,反馈:
1 | downgrade parquet to 1.8.2 to fix 1.9.0 connection leaks |
降级parquet库版本为1.8.2修复此问题,升级最新版本也是能解决问题,不过部分接口大动,导致不兼容,经过考虑决定降级库,而不该任何代码解决问题。
修复代码 by https://github.com/apache/parquet-mr/pull/388/files
1 | @Override |
总结
整个过程,由于全部服务容器化部署,导致排查问题周期比较长,获取日志还是比较原始的命令行方式,门槛较高,由于在现场发现问题,不能及时进行问题的追溯,只能根据只言片语的反馈进行问题追踪。如果不是在开发环境,复现此问题,整个问题排查起来异常困难,开始思考是否有tracking工具,可以快速定位问题。代码的最小化单元测试,只能定位范围,最终一直无法确定是某个函数直接导致的问题,代码编写中函数功能单一性拆分是一门学问。
期间,重启大发又一次发挥了奇效。在开发环境复现问题,并修复bug,patch修复各个产品线的不同版本。
如果,你还在用有连接泄漏问题的Parque版本,快快升级吧。