apache-impala-is-now-a-top-level-apache-project
在2017年11月28日,上午,apache宣布Impala晋升为apache顶级项目,这一令人振奋的消息。

五年前,cloudera计划开发一个全新的SQL引擎Apache Impala(这是第一个最快的Hadoop开源MPP SQL引擎),Impala融入了几十年来关系型数据库研究的经验教训和优势。Impala使用完全开放的形式融入Hadoop生态,允许用户使用SQL操作Hadoop中的海量数据,目前已经支持更多存储选择,比如:Apache Kudu、Amazon S3、Microsoft ADLS、本地存储等。
最初impala仅支持HDFS海量数据的交互式分析,其灵活性和领先的分析型数据库性能推动了Impala在全球企业中的大量部署。为企业业务提供BI和交互式SQL高效率分析支持,让支持impala的第三方生态系统快速增长。
三年前,cloudera将Impala捐赠给Apache Software Foundation以及最近宣布的Apache Kudu项目,进一步巩固了其在开源SQL领域的地位。自从捐赠Impala以来,社区一直保持高度活跃,希望引入更多的社区力量来繁荣社区,一直致力于创建一个积极创新的社区生态。现在impala从孵化项目晋升为一个Top-Level Apache Software Foundation Project。
Cloudera的Jim Apple是Apache Impala的重要导师,并且即将担任副总裁,他将持续以Apache way的方式指导和发展开源社区。
这是impala项目及社区非常重要的时刻,未来Impala将拥有更大规模的运行,为在云端持续优化减轻工作负载而努力。期待更多人参与推动impala的发展。
- 资源列表:
- 项目地址: https://impala.apache.org
- 邮件列表:
- 使用者: [email protected]
- 开发者: [email protected]
- 论坛:https://community.cloudera.com/t5/Interactive-Short-cycle-SQL/bd-p/Impala
- 如何贡献:https://cwiki.apache.org/confluence/display/IMPALA/Contributing+to+Impala
- Issues: https://issues.apache.org/jira/browse/IMPALA
- twitter:https://twitter.com/ApacheImpala
Apache Impala是一个开源的,原生的Apache Hadoops数据库分析引擎,Apache Impala支持者Cloudera, MapR, Oracle, and Amazon.
Impala解决Hadoop生态圈无法支持交互式查询的数据分析痛点,早期出现语法完全兼容Hive,现在逐渐支持更多语法,在底层数据库分析join中的优化是有很多创新之处的,特别是针对分布式数据库执行器的优化,利用Bloom Filter让join性能有很大的提升,目前impala建议使用的文件格式是Parquet。
Impala是一个分布式并行MPP SQL引擎在大数据上的实现,底层调度算法非常灵活,可支持HDFS多副本本地化计算在合并,效率非常高,而且是一个C++实现引擎能高效率使用硬件资源,融入了很多传统关系数据库的设计优势,在分布式查询有很多创新点,融合LLVM优化提升性能,它是一个OLAP引擎。
Impala和HDFS结合做海量数据的交互式分析ad-hoc查询,OLAP场景,BI报表可视化的最佳选择。
Impala和Kudu结合做海量数据的交互式查询,可支持CRUD操作,对强一致性事物要求不高的场景可以使用。
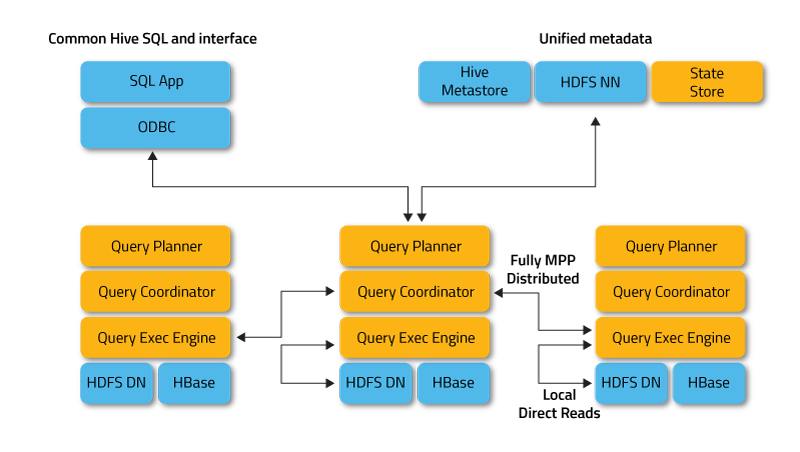
Impala可以无缝融入现有Hadoop集群,支持直接hive中的数据,完全兼容hive语法。直接可读取Hbase中数据,目前还支持Kudu,为了本地化计算符合Hadoop架构设计,impala部署需要遵守一定的原则。Impalad必须和DataNode、Hbase region server部署在一个节点上,StateStore、catalogd和NameNode部署在同一个节点上。

Impala Daemon: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询请求(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java 前端解释 SQL 查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。同时 Impalad 也与 State Store 保持连接,用于确定哪个 Impalad 是健康和可以接受新的工作。
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,由 statestored 进程表示,它通过创建多个线程来处理 Impalad 的注册订阅和与各 Impalad 保持心跳连接,各 Impalad 都会缓存一份 State Store 中的信息,当 State Store 离线后(Impalad 发现 State Store 处于离线时,会进入 recovery 模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数据)因为 Impalad 有 State Store 的缓存仍然可以工作,但会因为有些 Impalad 失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
Impala Catalog service: 被称为catalog service的Impala组件中继SQL 语句导致的元数据更改到集群中的所有节点。通常由物理进程catalogd 表示。集群中只需要一个这样的节点。由于请求通过statestored,因此statestored和catalogd 可以运行在同一节点。
CLI: 提供给用户查询使用的命令行工具(Impala Shell 使用 python 实现),同时 Impala 还提供了 Hue,JDBC, ODBC 使用接口。
这里说一个Impala坑,由于他没有直接存储元数据信息,而是靠从Hive Metastore定期同步,因为impalad任何一个节点都有可能充当协调者和执行者的角色,所以元数据信息需要所有节点存储最新的数据,这是为了兼容Hive而导致的一些遗留问题。Statestored模块的作用是实现一个业务无关的订阅(Subscribe)发布(Publish)系统,元数据的更改需要它去进行通知各个节点,这解决了一个MPP无法大规模扩展的问题,大大增加了系统的可扩展性,降低了catalogd的实现和运维复杂度。但是,带来一个问题,由于impalad可以直接提供jdbc服务,如果连接的任意impalad创建表,那么其他节点短期内是不知道这个表已经存在并且提供服务的,这个时候,如何解决,需要你每次只需SQL的时候都去执行INVALIDATE METADATA Statement,否则无法及时查询到最新的数据。
如果出现,底层HDFS抽取大量分区数据入库,不执行INVALIDATE METADATA Statement则无法查询到最新的数据,这个时候,我们客户就通过ETL Server每隔30秒就执行全局的metadata更新,导致impalad底层疯狂的去ScanHDFS上的数据,日志在后台一直疯狂刷新block信息。导致impala急剧下降,甚至一个SQL很久都无法返回结果的情况。只有简单查询才能有结果。所以一定要慎用、合理的用INVALIDATE METADATA。
我是在2013年9月,开始接触Impala了,当时就是利用impala做hive结果数据的bi报告对接查询,效果非常不错,甚至在很长一段时间,Hadoop生态都没有出现和impala进行pk的类似软件,它是SQL on Hadoop领域唯一原生的交互式SQL查询引擎。现在出现的竞争对手有Hive on Tez(0.8+ LLAP)、GreenPlum on Hadoop、Drill、PrestoDB等。
- Hive on Tez(LLAP)低延迟无法媲美Impala,交互式ad-hoc响应不够快
- GreenPlum on Hadoop没有和Hadoop结合的那么紧密,优势SQL语法全,优化器实现好
- PrestoDB早期测试过也出过报告,稳定性太差,内存管理功能都没有,压力大节点直接失去联系
- Drill性能表现不错,支持很多数据源,功能上有些类似PrestoDB
Impala on Hbase一般不建议使用,效率太低下,甚至还没有Hive效率高。可参考我做的性能测试相关文章。
Impala on Kudu已经可以使用在生产,面对那种事务性要求不高,但是需要CURD的场景很合适。
总体看来,impala未来在云端SQL on Cloud场景也会非常有前景,底层同时支持OLAP/OLTP,非常值得期待,所以现在更多投资在Impala中吧。