HDFS & MapReduce异构存储性能测试白皮书
title: HDFS & MapReduce异构存储性能测试白皮书
author: whoami
categories: Storage
tags: HDFS
date: 2016-10-27
description: The Truth About MapReduce Performance on SSD、STAT
- 摘要
我们已经进入数据时代,很难评估电子存储数据的总量,但是IDC评估2013年数据量为4.4Zettabytes,预计到2020年数据会增长十倍到44Zettabytes。如何高效处理每年生成的巨量的数据?处理大规模数据需要并行计算和存储架构,Hadoop提供了并行的,可扩展的,可靠地架构,本白皮书中展示了Hadoop使用SSD的性能与使用SATA的性能。
- Hadoop介绍
Hadoop使用HDFS文件系统,HDFS是一个高可扩展,并行文件系统,它为顺序数据集做了大量的优化,它跑在普通的硬件集群上。CPU和内存每秒可以处理数百GB的数据,但是硬盘IO每秒仅可以处理 100MB到几个GB的数据。硬盘IO是整个系统的性能瓶颈。每天大量数据生成,随着数据量的增长,处理数据需要越来越长的时间。如何节省时间?解决硬盘IO性能瓶颈的问题,提升 HDFS的性能。添加更多的硬盘到每个机器?可能机器已经没有更多的硬盘空间。即便有更多的空间,添加硬盘的方式提升性能也是不够好的。添加更多的机器可能数据中心没有更多的空间,而且添加系统开销太大。不用急,SSD帮你解决了这个问题。我们用更少的机器提供更高的性能。
- 测试集群配置
HDFS是用JAVA编写的分布式的,可扩展的,轻便的文件系统,它为Hadoop框架服务。一个Hadoop集群通常有一个Name node, 和一群data node.每个数据节点以块数据的方式按照HDFS规定的块协议跨越网络存储数据。文件系统通过TCP/IP套接字来通信。客户端之间使用PRC通信。测试集群有一个master node,其上运行 NameNode, ResourceManager and client 功能,4个datanodes。
硬件配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Hadoop未配置加速卡
CPU: 2*E5 2660V3
内存: 128GB
硬盘: 4TB 12*SATA 7200
网络环境: 万兆光纤网络
分区方式: LVM分区方式
Hadoop配置加速卡
CPU: 2*E5 2660V3
内存: 128GB
硬盘: 4TB 12*SATA 7200 1T*SSD
网络环境: 万兆光纤网络
分区方式: LVM分区方式
声明:每台主机中存在一块SSD磁盘1T加速,12块SATA磁盘。测试流程
测试的目的是评估 HDFS 基于SATA SSD 的性能。
TestDFSIO 评估 HDFS 的性能,给网络和存储 IO 加压。读写文件的命令可以度量NameNode 和DataNodes 系统级的性能及展示网络的瓶颈,大量的 MapReduce 负载时 IO 密集的而非计算密集,所以在这种情况下 TestDFSIO 可以提供一个初始的情况。
测试结果
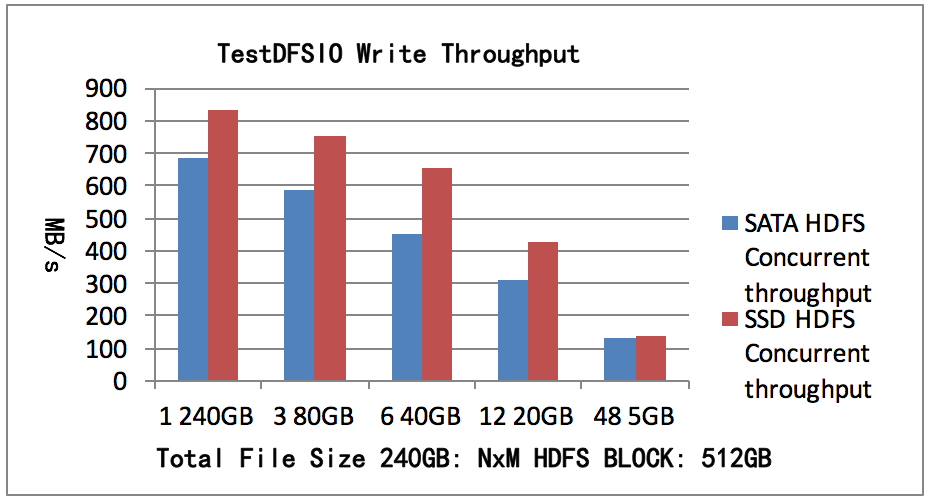
我们的测试运行在 Namenode 上。测试总写入数据240GB,副本数3,文件数N为1, 3, 6, 12, 48文件大小为M,每个文件一个map。测试结果如图1所示,SATA HDFS测试1个map可以获得并发吞吐率685MB/s。 SSD HDFS测试1个map可以获得并发吞吐率830MB/s。
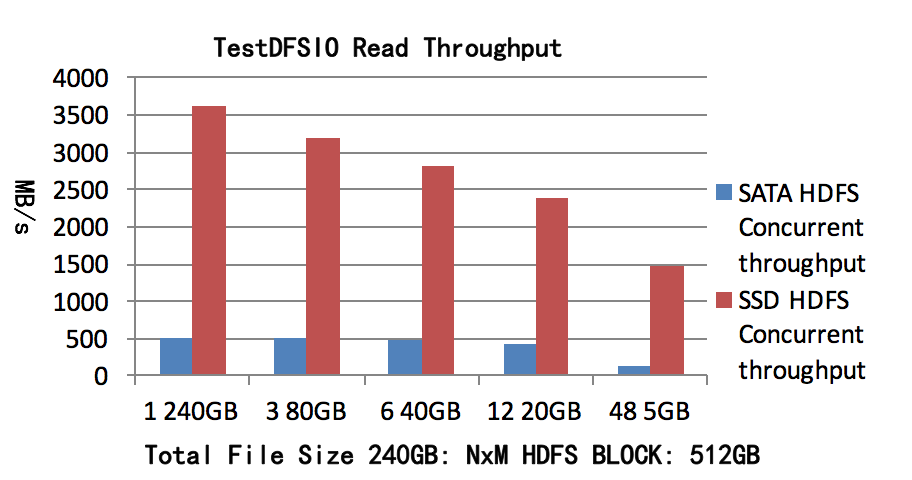
测试总读取数据 240GB, 副本数3,文件数N为1,3,6,12,48文件大小为M,每个文件一个map。测试结果如图2所示,SATA HDFS测试1个map可以获得并发吞吐率501MB/s,SSD
HDFS测试1个map可以获得的并发吞吐率3625MB/s。
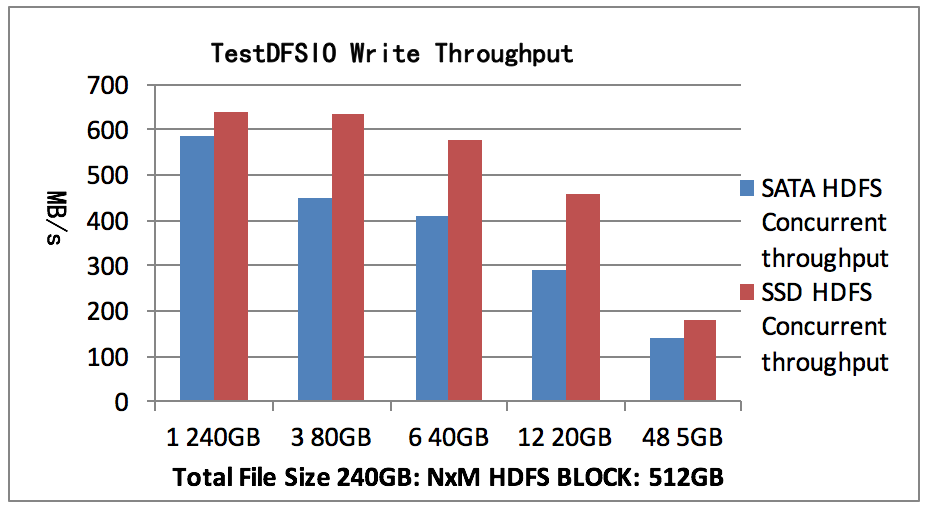
我们的测试运行在 Namenode 上。测试总写入数据240GB,副本数2,文件数N为1, 3, 6, 12, 48文件大小为M,每个文件一个map。测试结果如图3所示,SATA HDFS测试1个map可以获得并发吞吐率587MB/s。 SSD HDFS测试1个map可以获得并发吞吐率638MB/s。
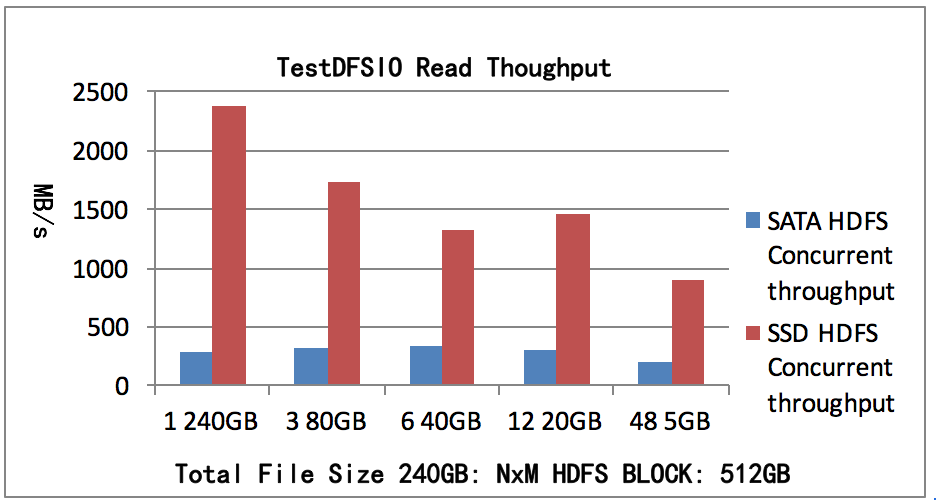
测试总读取数据 240GB, 副本数2,文件数N为1,3,6,12,48文件大小为M,每个文件一个map。测试结果如图4所示,SATA HDFS测试1个map可以获得并发吞吐率295MB/s,SSD
HDFS测试1个map可以获得的并发吞吐率2379MB/s。
- The Truth About MapReduce Performance on SSD、STAT
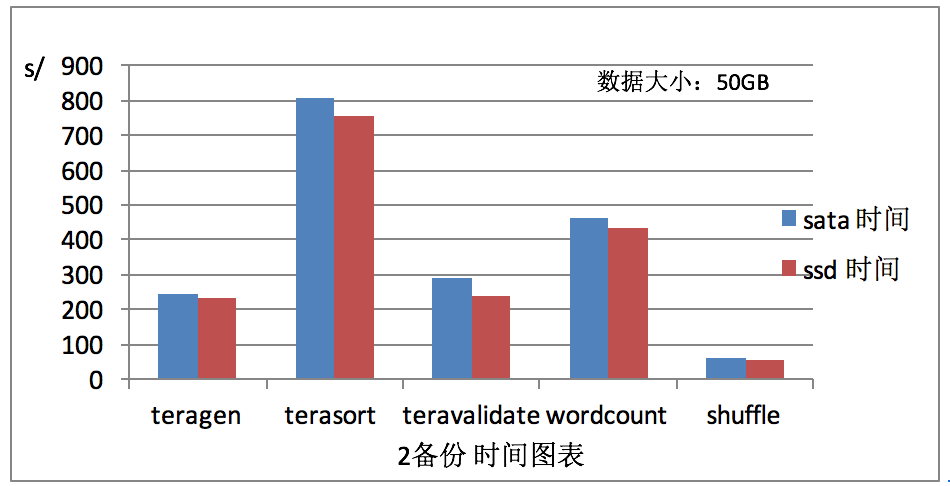
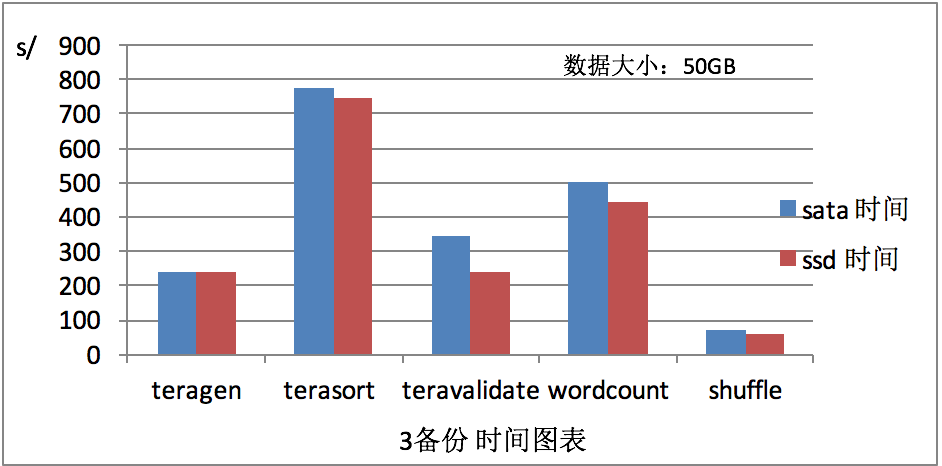
在不同的磁盘中测试mapReduce不同算法的计算时间,
- MapReduce算法描述
Teragen 大量使用网路工作进行HDFS三备份复制
terasort HDFS读写的工作比
teravalidate HDFS包含大量读取操作的工作,HDFS写一些小的IO
wordcount CPU-heavy工作量大
shuffle hadoop-examples randomtextwriter shuffle-only工作修改
- HDFS PUT vs HDFS FUSE vs HDFS NFSGateway
单文件大小10G1
2
3hdfs-put 0m32.639s
hdfs-fuse 1m17.294s
hdfs-nfsgateway 1m58.294s
- 结论
随着海量数据的增长,提供 Hadoop IO 性能的最有效的方法是使用 SSD替代SATA。本白皮书清晰的展示了SSD 极大的提升了 Hadoop 集群的性能,同时减少了节点数量,大幅度降低了TCO。
对于mapReduce,通过图5,图6,可以看出shuffle算法计算用时最短,我们的测试也表明,固态硬盘的好处取决于所涉及的MapReduce工作,因此,存储介质的选择需要考虑这个生产工作负载聚合性能的影响,精确地改善取决于可压缩数据在所有的数据集、IO和CPU负载的比例工作。