Running MapReduce Example Programs and Benchmarks
When using new or updated hardware or software, simple examples and benchmarks help confirm proper operation. Apache Hadoop includes many examples and benchmarks to aid in this task. This chapter from Hadoop 2 Quick-Start Guide: Learn the Essentials of Big Data Computing in the Apache Hadoop 2 Ecosystem provides instructions on how to run, monitor, and manage some basic MapReduce examples and benchmarks.
- The steps needed to run the Hadoop MapReduce examples are provided.
- An overview of the YARN ResourceManager web GUI is presented.
- The steps needed to run two important benchmarks are provided.
- The mapred command is introduced as a way to list and kill MapReduce jobs.
When using new or updated hardware or software, simple examples and benchmarks help confirm proper operation. Apache Hadoop includes many examples and benchmarks to aid in this task. This chapter provides instructions on how to run, monitor, and manage some basic MapReduce examples and benchmarks.
Running MapReduce Examples
All Hadoop releases come with MapReduce example applications. Running the existing MapReduce examples is a simple process—once the example files are located, that is. For example, if you installed Hadoop version 2.6.0 from the Apache sources under /opt, the examples will be in the following directory:
1 | /opt/hadoop-2.6.0/share/hadoop/mapreduce/ |
In other versions, the examples may be in /usr/lib/hadoop-mapreduce/ or some other location. The exact location of the example jar file can be found using the find command:
1 | $ find / -name "hadoop-mapreduce-examples*.jar" -print |
For this chapter the following software environment will be used:
- OS: Linux
- Platform: RHEL 6.6
- Hortonworks HDP 2.2 with Hadoop Version: 2.6
In this environment, the location of the examples is /usr/hdp/2.2.4.2-2/hadoop-mapreduce. For the purposes of this example, an environment variable called HADOOP_EXAMPLES can be defined as follows:
1 | $ export HADOOP_EXAMPLES=/usr/hdp/2.2.4.2-2/hadoop-mapreduce |
Once you define the examples path, you can run the Hadoop examples using the commands discussed in the following sections.
Listing Available Examples
A list of the available examples can be found by running the following command. In some cases, the version number may be part of the jar file (e.g., in the version 2.6 Apache sources, the file is named hadoop-mapreduce-examples-2.6.0.jar).
1 | $ yarn jar $HADOOP_EXAMPLES/hadoop-mapreduce-examples.jar |
In previous versions of Hadoop, the command hadoop jar . . . was used to run MapReduce programs. Newer versions provide the yarn command, which offers more capabilities. Both commands will work for these examples.
The possible examples are as follows:
1 | An example program must be given as the first argument. |
To illustrate several features of Hadoop and the YARN ResourceManager service GUI, the pi and terasort examples are presented next. To find help for running the other examples, enter the example name without any arguments. Chapter 6, “MapReduce Programming,” covers one of the other popular examples called wordcount.
Running the Pi Example
The pi example calculates the digits of π using a quasi-Monte Carlo method. If you have not added users to HDFS (see Chapter 10, “Basic Hadoop Administration Procedures”), run these tests as user hdfs. To run the pi example with 16 maps and 1,000,000 samples per map, enter the following command:
1 | $ yarn jar $HADOOP_EXAMPLES/hadoop-mapreduce-examples.jar pi 16 1000000 |
If the program runs correctly, you should see output similar to the following. (Some of the Hadoop INFO messages have been removed for clarity.)
1 | Number of Maps = 16 |
Notice that the MapReduce progress is shown in the same way as Hadoop version 1, but the application statistics are different. Most of the statistics are self-explanatory. The one important item to note is that the YARN MapReduce framework is used to run the program. (See Chapter 1, “Background and Concepts,” and Chapter 8, “Hadoop YARN Applications,” for more information about YARN frameworks.)
Using the Web GUI to Monitor Examples
This section provides an illustration of using the YARN ResourceManager web GUI to monitor and find information about YARN jobs. The Hadoop version 2 YARN ResourceManager web GUI differs significantly from the MapReduce web GUI found in Hadoop version 1. Figure 4.1 shows the main YARN web interface. The cluster metrics are displayed in the top row, while the running applications are displayed in the main table. A menu on the left provides navigation to the nodes table, various job categories (e.g., New, Accepted, Running, Finished, Failed), and the Capacity Scheduler (covered in Chapter 10, “Basic Hadoop Administration Procedures”). This interface can be opened directly from the Ambari YARN service Quick Links menu or by directly entering http://hostname:8088 into a local web browser. For this example, the pi application is used. Note that the application can run quickly and may finish before you have fully explored the GUI. A longer-running application, such as terasort, may be helpful when exploring all the various links in the GUI.
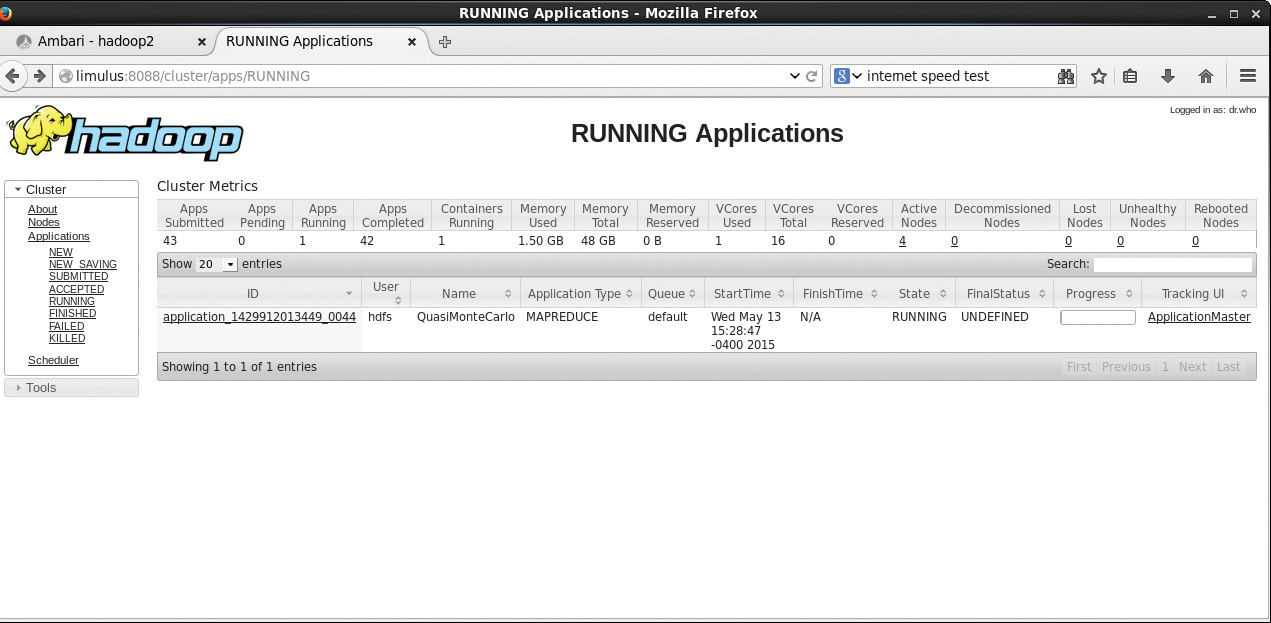
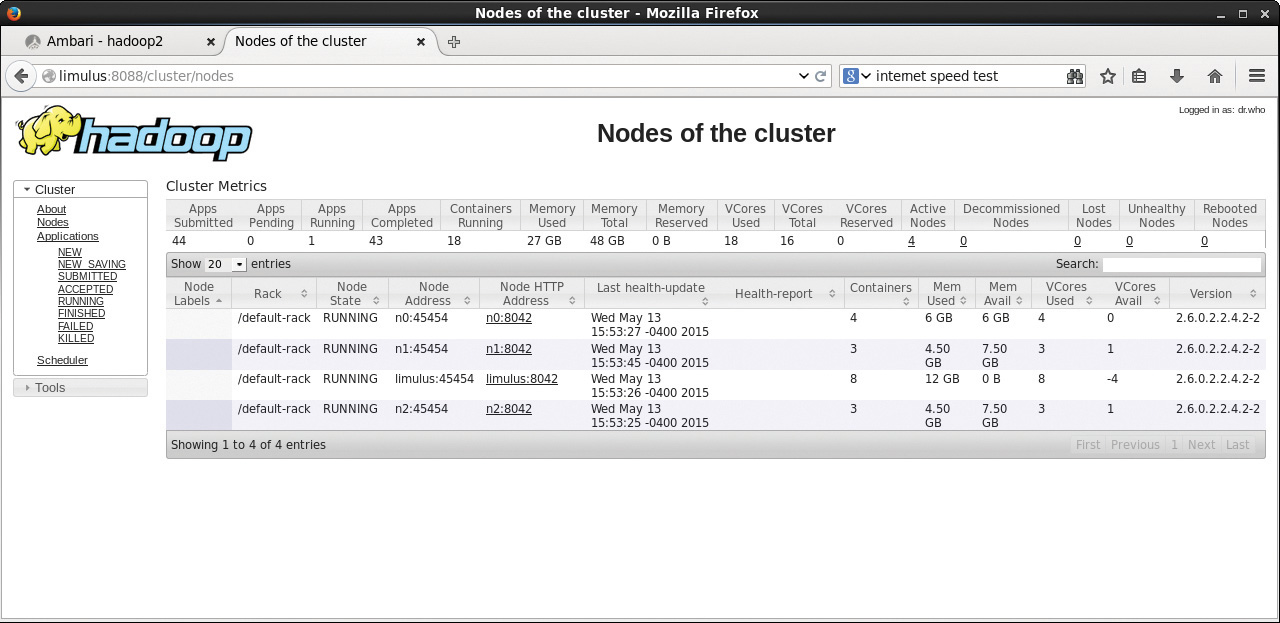
Metrics table, you will see some new information. First, you will notice that the “Map/Reduce Task Capacity” has been replaced by the number of running containers. If YARN is running a MapReduce job, these containers can be used for both map and reduce tasks. Unlike in Hadoop version 1, the number of mappers and reducers is not fixed. There are also memory metrics and links to node status. If you click on the Nodes link (left menu under About), you can get a summary of the node activity and state. For example, Figure 4.2 is a snapshot of the node activity while the pi application is running. Notice the number of containers, which are used by the MapReduce framework as either mappers or reducers.
Going back to the main Applications/Running window (Figure 4.1), if you click on the application_14299… link, the Application status window in Figure 4.3 will appear. This window provides an application overview and metrics, including the cluster node on which the ApplicationMaster container is running.
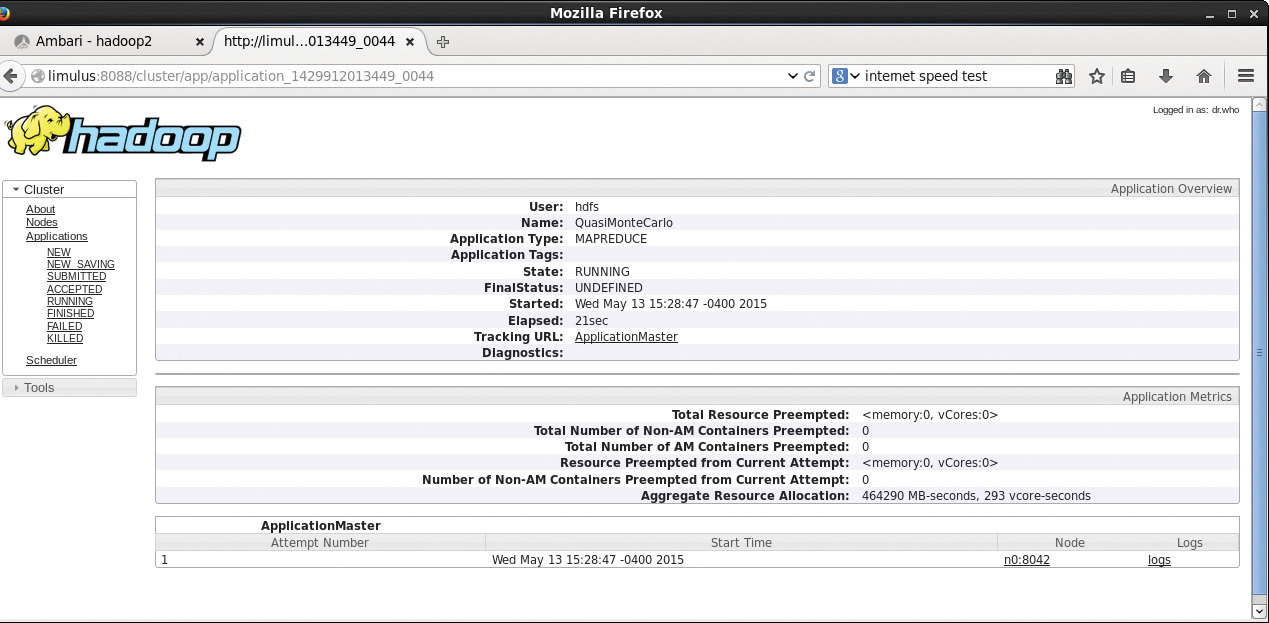
Clicking the ApplicationMaster link next to “Tracking URL:” in Figure 4.3 leads to the window shown in Figure 4.4. Note that the link to the application’s ApplicationMaster is also found in the last column on the main Running Applications screen shown in Figure 4.1.
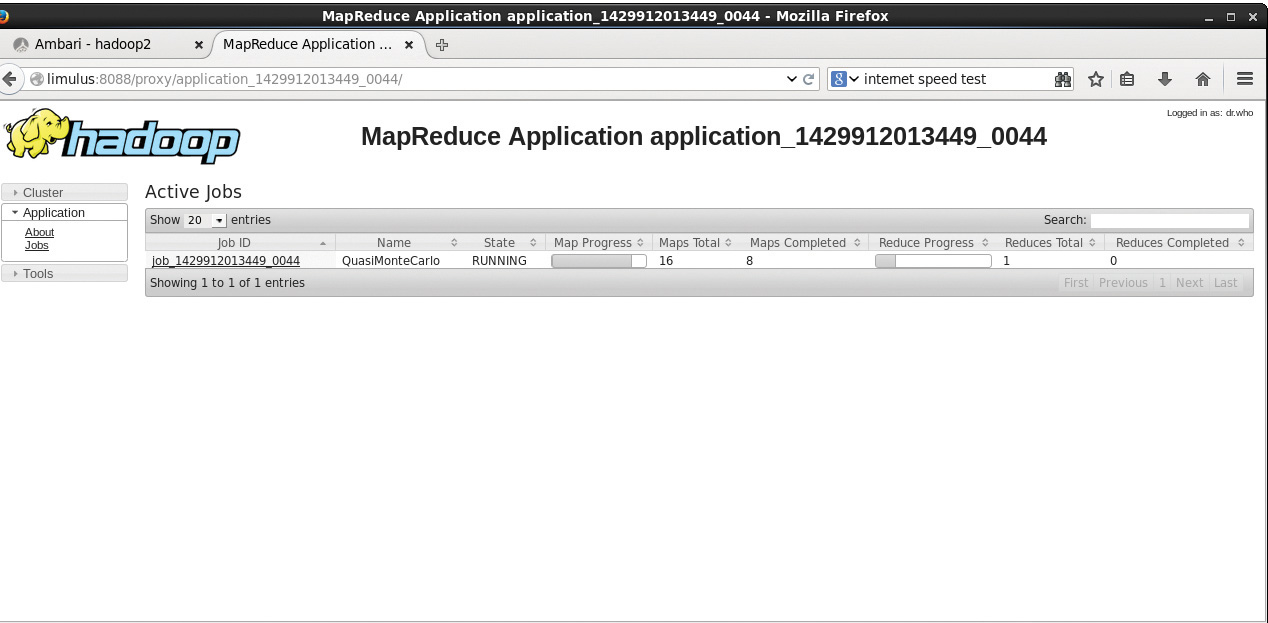
In the MapReduce Application window, you can see the details of the MapReduce application and the overall progress of mappers and reducers. Instead of containers, the MapReduce application now refers to maps and reducers. Clicking job_14299… brings up the window shown in Figure 4.5. This window displays more detail about the number of pending, running, completed, and failed mappers and reducers, including the elapsed time since the job started.
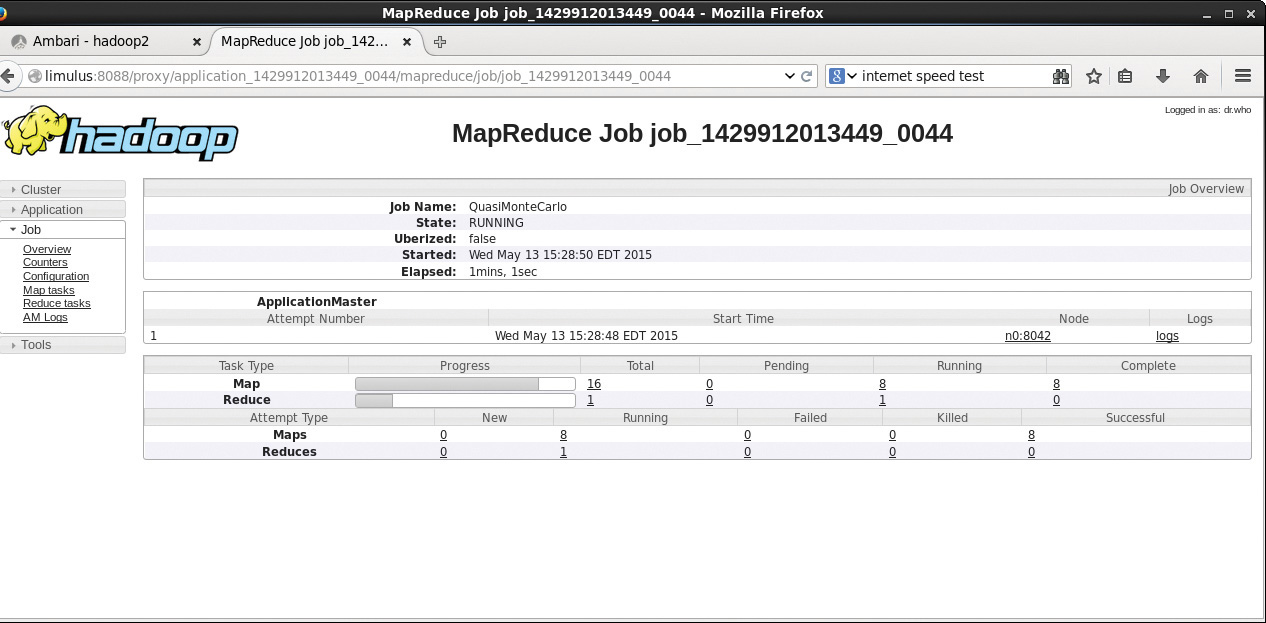
The status of the job in Figure 4.5 will be updated as the job progresses (the window needs to be refreshed manually). The ApplicationMaster collects and reports the progress of each mapper and reducer task. When the job is finished, the window is updated to that shown in Figure 4.6. It reports the overall run time and provides a breakdown of the timing of the key phases of the MapReduce job (map, shuffle, merge, reduce).
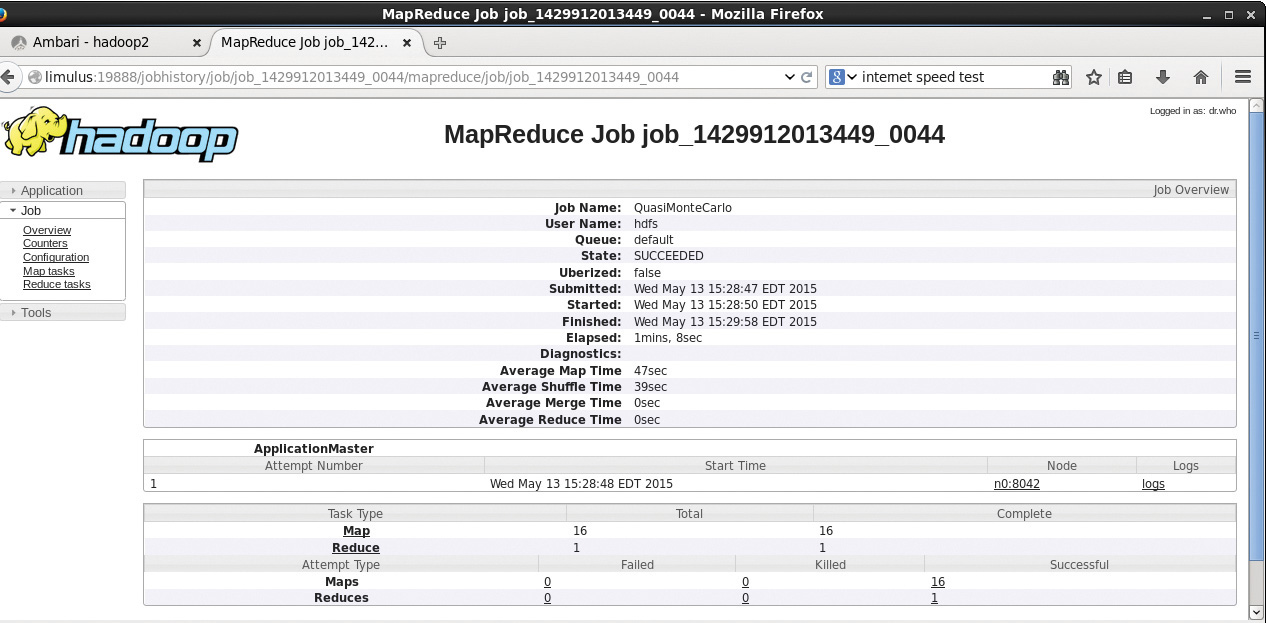
If you click the node used to run the ApplicationMaster (n0:8042 in Figure 4.6), the window in Figure 4.7 opens and provides a summary from the NodeManager on node n0. Again, the NodeManager tracks only containers; the actual tasks running in the containers are determined by the ApplicationMaster.
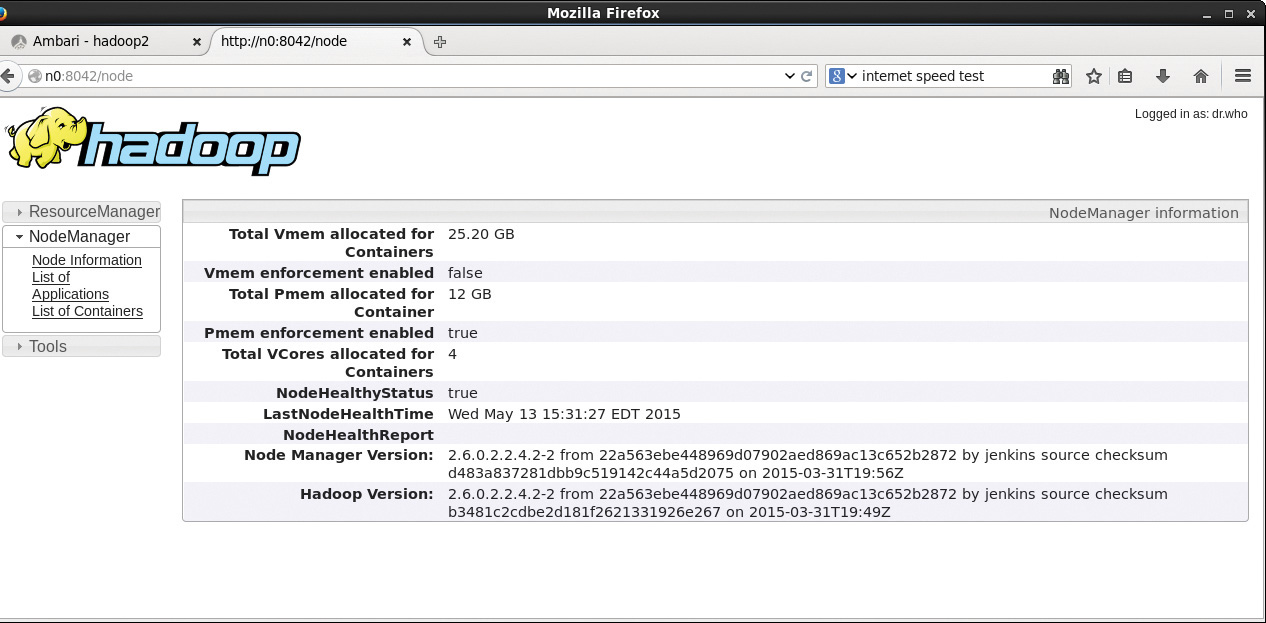
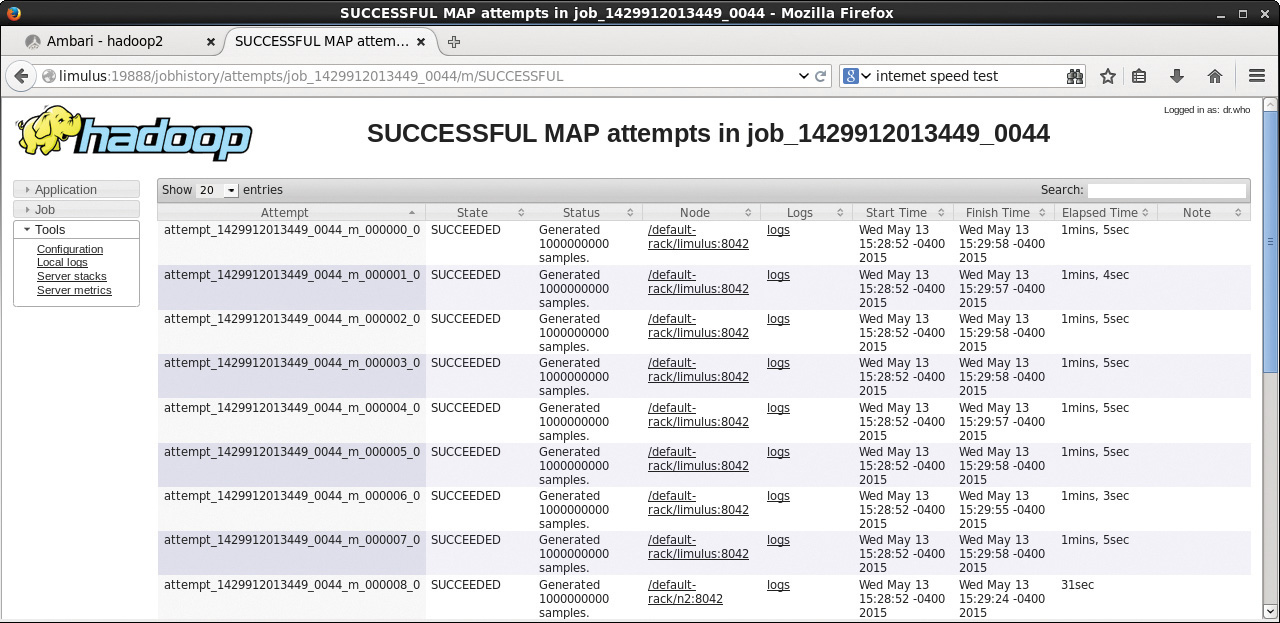
Going back to the job summary page (Figure 4.6), you can also examine the logs for the ApplicationMaster by clicking the “logs” link. To find information about the mappers and reducers, click the numbers under the Failed, Killed, and Successful columns. In this example, there were 16 successful mappers and one successful reducer. All the numbers in these columns lead to more information about individual map or reduce process. For instance, clicking the “16” under “-Successful” in Figure 4.6 displays the table of map tasks in Figure 4.8. The metrics for the Application Master container are displayed in table form. There is also a link to the log file for each process (in this case, a map process). Viewing the logs requires that the yarn.log.aggregation-enable variable in the yarn-site.xml file be set. For more on changing Hadoop settings, see Chapter 9, “Managing Hadoop with Apache Ambari.”
If you return to the main cluster window (Figure 4.1), choose Applications/Finished, and then select our application, you will see the summary page shown in Figure 4.9.
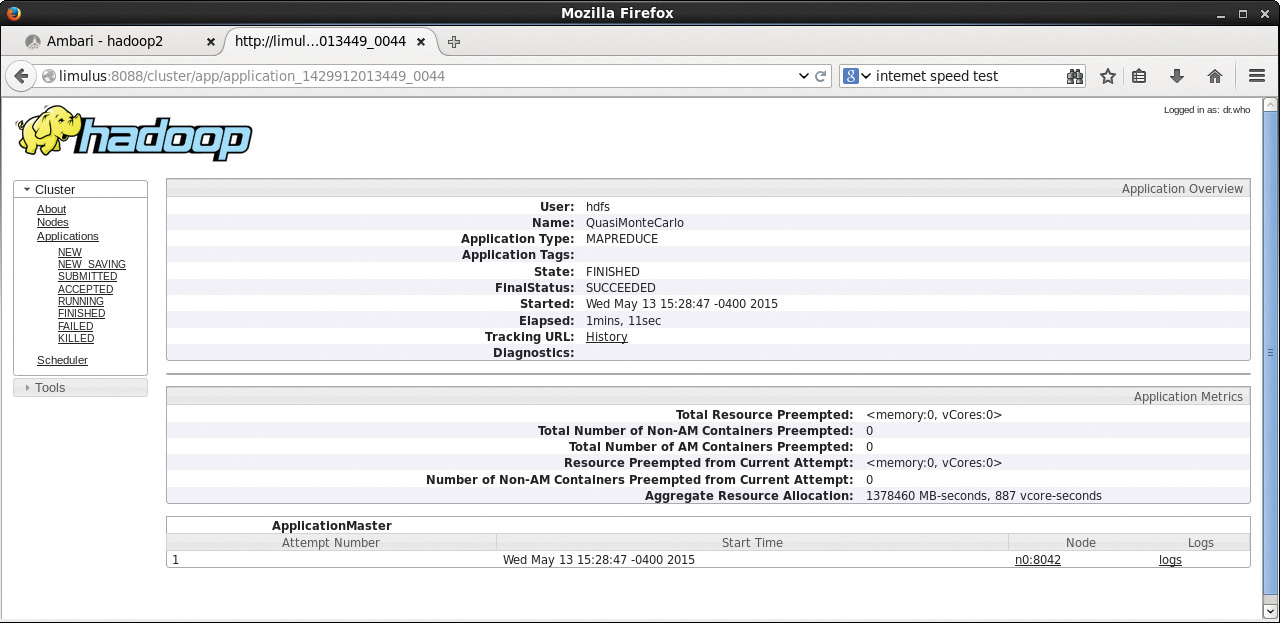
There are a few things to notice in the previous windows. First, because YARN manages applications, all information reported by the ResourceManager concerns the resources provided and the application type (in this case, MAPREDUCE). In Figure 4.1 and Figure 4.4, the YARN ResourceManager refers to the pi example by its application-id (application_1429912013449_0044). YARN has no data about the actual application other than the fact that it is a MapReduce job. Data from the actual MapReduce job are provided by the MapReduce framework and referenced by a job-id (job_1429912013449_0044) in Figure 4.6. Thus, two clearly different data streams are combined in the web GUI: YARN applications and MapReduce framework jobs. If the framework does not provide job information, then certain parts of the web GUI will not have anything to display.
Another interesting aspect of the previous windows is the dynamic nature of the mapper and reducer tasks. These tasks are executed as YARN containers, and their number will change as the application runs. Users may request specific numbers of mappers and reducers, but the ApplicationMaster uses them in a dynamic fashion. As mappers complete, the ApplicationMaster will return the containers to the ResourceManager and request a smaller number of reducer containers. This feature provides for much better cluster utilization because mappers and reducers are dynamic—rather than fixed—resources.
Running Basic Hadoop Benchmarks
Many Hadoop benchmarks can provide insight into cluster performance. The best benchmarks are always those that reflect real application performance. The two benchmarks discussed in this section, terasort and TestDFSIO, provide a good sense of how well your Hadoop installation is operating and can be compared with public data published for other Hadoop systems. The results, however, should not be taken as a single indicator for system-wide performance on all applications.
The following benchmarks are designed for full Hadoop cluster installations. These tests assume a multi-disk HDFS environment. Running these benchmarks in the Hortonworks Sandbox or in the pseudo-distributed single-node install from Chapter 2 is not recommended because all input and output (I/O) are done using a single system disk drive.
Running the Terasort Test
The terasort benchmark sorts a specified amount of randomly generated data. This benchmark provides combined testing of the HDFS and MapReduce layers of a Hadoop cluster. A full terasort benchmark run consists of the following three steps:
Generating the input data via teragen program.
Running the actual terasort benchmark on the input data.
Validating the sorted output data via the teravalidate program.
In general, each row is 100 bytes long; thus the total amount of data written is 100 times the number of rows specified as part of the benchmark (i.e., to write 100GB of data, use 1 billion rows). The input and output directories need to be specified in HDFS. The following sequence of commands will run the benchmark for 50GB of data as user hdfs. Make sure the /user/hdfs directory exists in HDFS before running the benchmarks.
- Run teragen to generate rows of random data to sort.
1 | $ yarn jar $HADOOP_EXAMPLES/hadoop-mapreduce-examples.jar teragen 500000000 |
Example results are as follows (date and time prefix removed).
1 | fs.TestDFSIO: ----- TestDFSIO ----- : write |
2.Run terasort to sort the database.
1 | $ yarn jar $HADOOP_EXAMPLES/hadoop-mapreduce-client-jobclient-tests.jar |
Example results are as follows (date and time prefix removed). The large standard deviation is due to the placement of tasks in the cluster on a small four-node cluster.
1 | fs.TestDFSIO: ----- TestDFSIO ----- : read |
3.Clean up the TestDFSIO data.
1 | $ yarn jar $HADOOP_EXAMPLES/hadoop-mapreduce-client-jobclient-tests.jar |
Running the TestDFSIO and terasort benchmarks help you gain confidence in a Hadoop installation and detect any potential problems. It is also instructive to view the Ambari dashboard and the YARN web GUI (as described previously) as the tests run.
Managing Hadoop MapReduce Jobs
Hadoop MapReduce jobs can be managed using the mapred job command. The most important options for this command in terms of the examples and benchmarks are -list, -kill, and -status. In particular, if you need to kill one of the examples or benchmarks, you can use the mapred job -list command to find the job-id and then use mapred job -kill
1 | $ mapred job |
Summary and Additional Resources
No matter what the size of the Hadoop cluster, confirming and measuring the MapReduce performance of that cluster is an important first step. Hadoop includes some simple applications and benchmarks that can be used for this purpose. The YARN ResourceManager web GUI is a good way to monitor the progress of any application. Jobs that run under the MapReduce framework report a large number of run-time metrics directly (including logs) back to the GUI; these metrics are then presented to the user in a clear and coherent fashion. Should issues arise when running the examples and benchmarks, the mapred job command can be used to kill a MapReduce job.
Additional information and background on each of the examples and benchmarks can be found from the following resources:
Pi Benchmark
Terasort Benchmark
Benchmarking and Stress Testing an Hadoop Cluster
- http://www.michael-noll.com/blog/2011/04/09/benchmarking-and-stress-testing-an-hadoop-cluster-with-terasort-testdfsio-nnbench-mrbench (uses Hadoop V1, will work with V2)
Configuring Heterogeneous Storage in HDFS
Archival Storage, SSD & Memory
The Truth About MapReduce Performance on SSDs
Memory Storage Support in HDFS